
GENERATIVE AI EVALUATION TOOLKIT
HumanELY: Human Evaluation of Large Language model Yield
To provide a structured way to perform human evaluation, we propose the first and the most comprehensive guidance and a web application called HumanELY. Our approach and tools derived from commonly used evaluation metrics helps perform evaluation of large language model outputs in a comprehensive, consistent, measurable and comparable manner.

HumanELY comprises of 5 key metrics of relevance, coverage, coherence, harm and comparison. Additional sub metrics within these metrics provide for a Likert scale based human evaluation of LLM outputs.
Publications:
GamELY: Generative AI method for Evaluation of LLM Yield
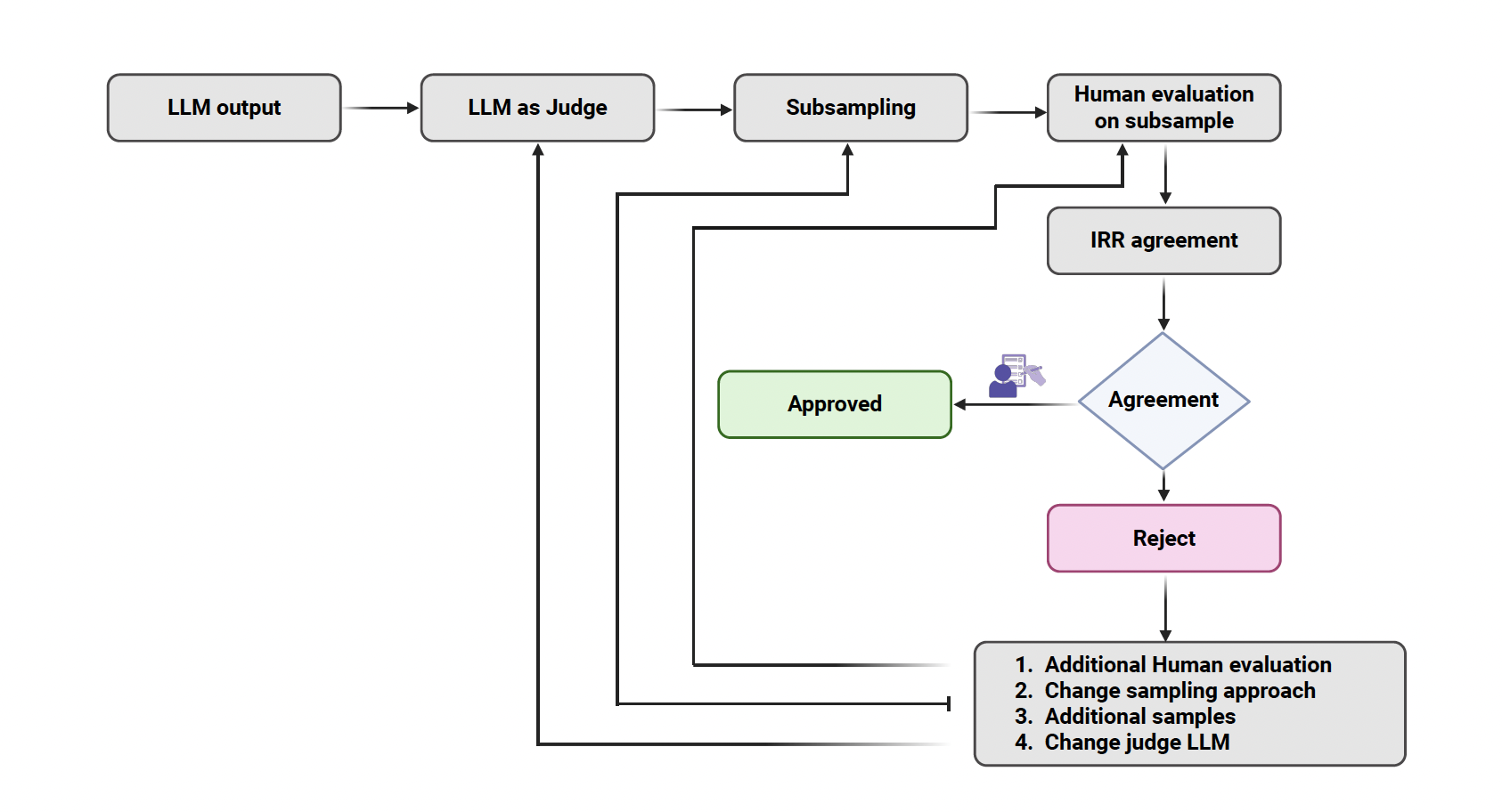
GamELY is a Human-in-the-Loop (HITL) framework for scalable human evaluation of LLMs in healthcare. GamELY, a Human-in-the-Loop (HITL) framework for scalable human evaluation of LLMs in healthcare. GamELY is a two-phase system: in the first phase, well-structured prompts are used to generate scores from LLMs across diverse human evaluation metrics (Relevance, Coverage, Coherence, Harm, and Comparison). The prompt uses the same metrics, assessment questions and scale as used for human evaluation,in HumanELY, to ensure uniformity in evaluation.The second phase involves subsampling of the full dataset for auditing, enabling humans to serve as the final judges while minimizing their workload. GamELY uses a Human-in-the-Loop (HITL) framework for scalable human evaluation of LLMs in healthcare.
Python package for GamELY: https://pypi.org/project/GamELY/
Publication: GamELY: Human-in-the loop Framework for Scaling Human Evaluation of LLMs in Healthcare.Raghav Awasthi, Nishant Singh, Shreya Mishra, Atharva Bhattad, Moises Auron, Charumathi Raghu Subramanian, Ashish Atreja, Kamal Maheshwari, Dwarikanath Mahapatra, Jacek B. Cywinski, Ashish Khanna, Francis Papay, and Piyush Mathur. 2025. Proceedings of the 16th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics. Association for Computing Machinery, New York, NY, USA, Article 48, 1–6. https://doi.org/10.1145/3765612.3767224